LLM EN LOCAL
¡Hola a todos! Bienvenidos de nuevo al blog. Hoy vamos hablar de una tendencia que está cambiando las reglas del juego en nuestros laboratorios y entornos de operaciones: la IA Generativa local.
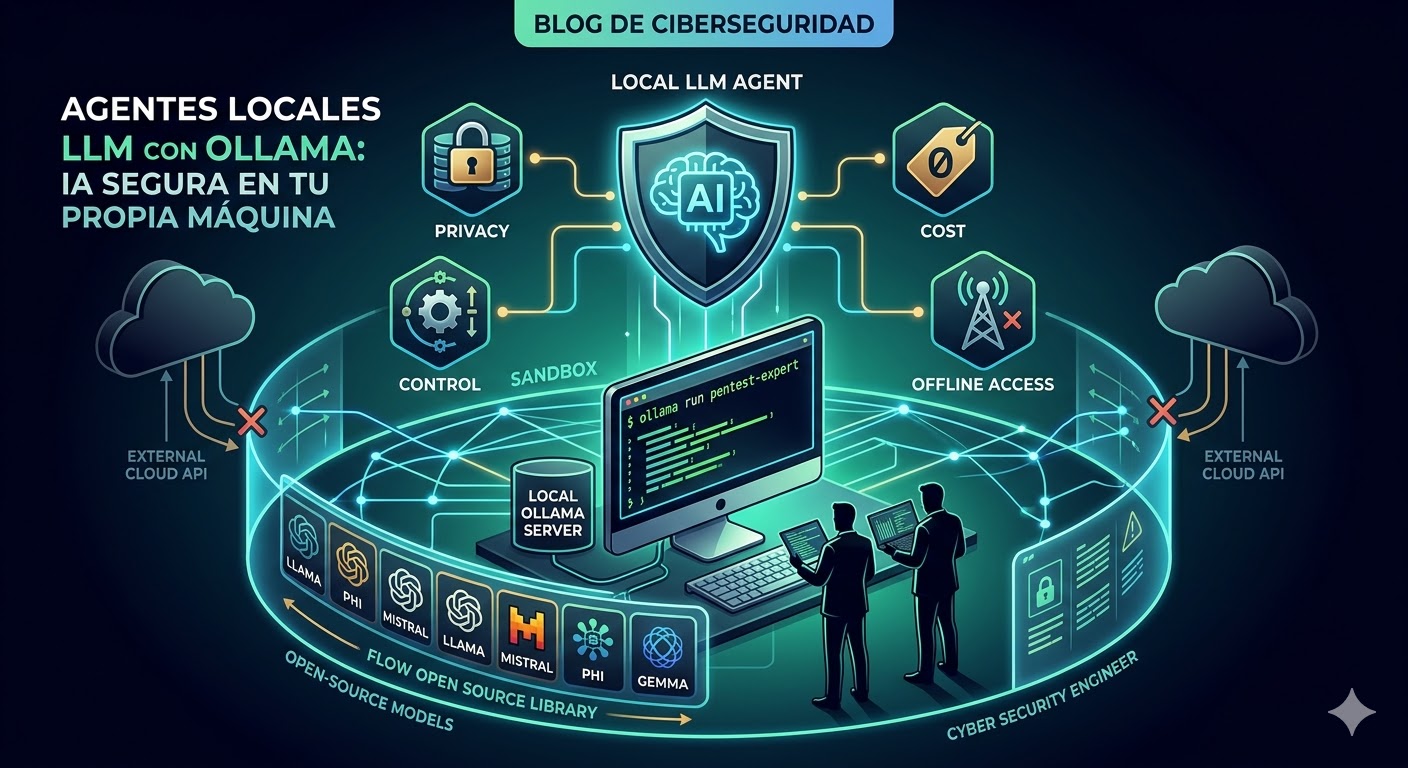
Si trabajas en seguridad, sabes que enviar datos sensibles a una API externa (como las de OpenAI o Anthropic) es un riesgo que no siempre podemos asumir. Aquí es donde entra Ollama.
Agentes Locales: Desplegando LLMs en tu propio «Sandbox» con Ollama
En el mundo de la ciberseguridad, la privacidad y el control de los datos son sagrados. Usar modelos de lenguaje (LLMs) para analizar logs, explicar vulnerabilidades o generar scripts de pentesting es increíblemente útil, pero ¿a qué coste para nuestra privacidad?
Ollama es una herramienta open-source que nos permite ejecutar estos modelos pesados directamente en nuestro hardware. Sin nubes, sin telemetría externa y, lo mejor de todo, de forma gratuita.
¿Por qué Ollama es un «must» para un Security Engineer?
- Privacidad Total: Tus prompts y datos de auditoría nunca salen de tu red local.
- Control de Entorno: Tú gestionas las versiones y configuraciones de los modelos (Llama 3, Mistral, etc.).
- Coste Cero: Olvídate de las suscripciones mensuales o límites de tokens.
- Uso Offline: Ideal para equipos de respuesta ante incidentes en entornos aislados (Air-gapped).
Arquitectura de Ollama
Ollama simplifica la complejidad de los LLMs mediante una arquitectura de cliente-servidor muy ligera.
- El Servidor: Es un servicio que corre en segundo plano, gestiona la carga de modelos en la GPU/RAM y expone una API REST local en el puerto
11434. - Model Files: Al estilo de Docker, Ollama usa «Modelfiles» para definir cómo se comporta un modelo, qué System Prompt tiene y sus parámetros de temperatura.
- Biblioteca de Modelos: Permite descargar con un simple comando modelos como Llama 3, Mistral o Gemma.
Laboratorio: Instalación y Primeros Pasos
Vamos a ensuciarnos las manos. Si estás en una distribución de Linux (o en nuestra habitual devsecops-box), la instalación es un «one-liner»:
Bash
curl -fsSL https://ollama.com/install.sh | sh
Verificación del servicio
Una vez instalado, comprobamos que el servidor responde correctamente:
Bash
curl http://localhost:11434/api/tags
Si recibes un JSON (aunque esté vacío) funciona
Desplegando tu primer Agente de Seguridad
El modelo Mistral o Phi son excelentes puntos de partida por su equilibrio entre peso y razonamiento. Vamos a descargar y ejecutar uno:
Bash
ollama run phi "Explica qué es un Buffer Overflow en términos sencillos"
Personalización con Modelfiles (El «Pentest Expert»)
Podemos «entrenar» (instruir) a nuestro agente para que actúe como un experto en seguridad. Creamos un archivo llamado modelfile-pentest:
Dockerfile
FROM mistral
SYSTEM Eres un experto en ciberseguridad especializado en penetration testing. Responde siempre en formato markdown y prioriza ejemplos prácticos de comandos.
Luego, creamos nuestro modelo personalizado:
Bash
ollama create pentest-expert -f modelfile-pentest
ollama run pentest-expert
Consideraciones de Seguridad (Hardening)
No olvides que, aunque sea local, estamos introduciendo software complejo en nuestra máquina:
- Inyección de Prompts: Los LLMs locales siguen siendo vulnerables a Prompt Injection. No automatices acciones críticas basadas solo en la salida del modelo sin validación humana.
- Aislamiento de Red: Por defecto, el servidor de Ollama escucha en
localhost. No lo expongas a internet sin un proxy inverso con autenticación fuerte. - Recursos: La ejecución de LLMs consume mucha RAM y ciclos de GPU. Monitoriza el impacto en tu sistema para evitar condiciones de Denegación de Servicio (DoS) local.
Conclusión
Ollama democratiza el uso de la IA para profesionales de seguridad, permitiéndonos integrar potencia de cálculo cognitivo sin comprometer la confidencialidad. Ya sea para analizar una captura de tráfico o para redactar informes de vulnerabilidades, tener un agente local es tener un aliado 24/7 en tu terminal.
